CVE-2021-26086 分析
漏洞背景
Limited Remote File Read in Jira Software Server - CVE-2021-26086 https://jira.atlassian.com/browse/JRASERVER-72695
影响版本:
- version < 8.5.14
- 8.6.0 ≤ version < 8.13.6
- 8.14.0 ≤ version < 8.16.1
修复版本:
- 8.5.14
- 8.13.6
- 8.16.1
- 8.17.0
看到这篇文章时 https://tttang.com/archive/1323/ 分析异常惊讶,这难道不是 tomcat 的基本处理逻辑,这怎么会出问题。后来才发现关键点和我理解的不一样,所以才有了这片分析,刚好对 tomcat 数据处理过程在做一遍梳理
先检查了一下 tomcat 版本,安装版本 8.16.0

tomcat 如何防止客户端直接访问 WEB-INF 目录
tomcat 不能直接访问 WEB-INF 和 META-INF目录
参考:https://www.html.cn/site/server/1142687689100.html
tomcat 中 在 context 容器处理时,如果以请求映射路径以 WEB-INF 或者 META-INF 开头,那么会返回 404
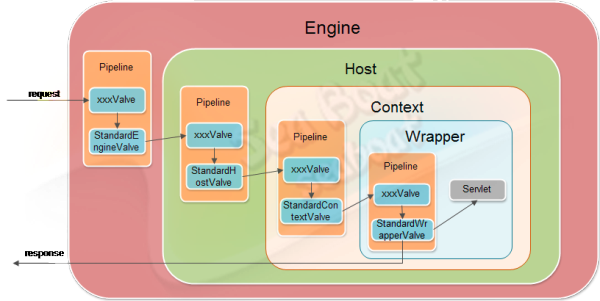
StandardContextValve 阻止了 对 WEB-INF 的访问
相应实现如下, org.apache.catalina.core.StandardContextValve 的判断逻辑如下,在交由Wrapper 容器处理之前,会先对请求 requsetPathMB 进行判断,如果以 META-INF 或者 WEB-INF 开头(忽略大小写),那么会响应 404
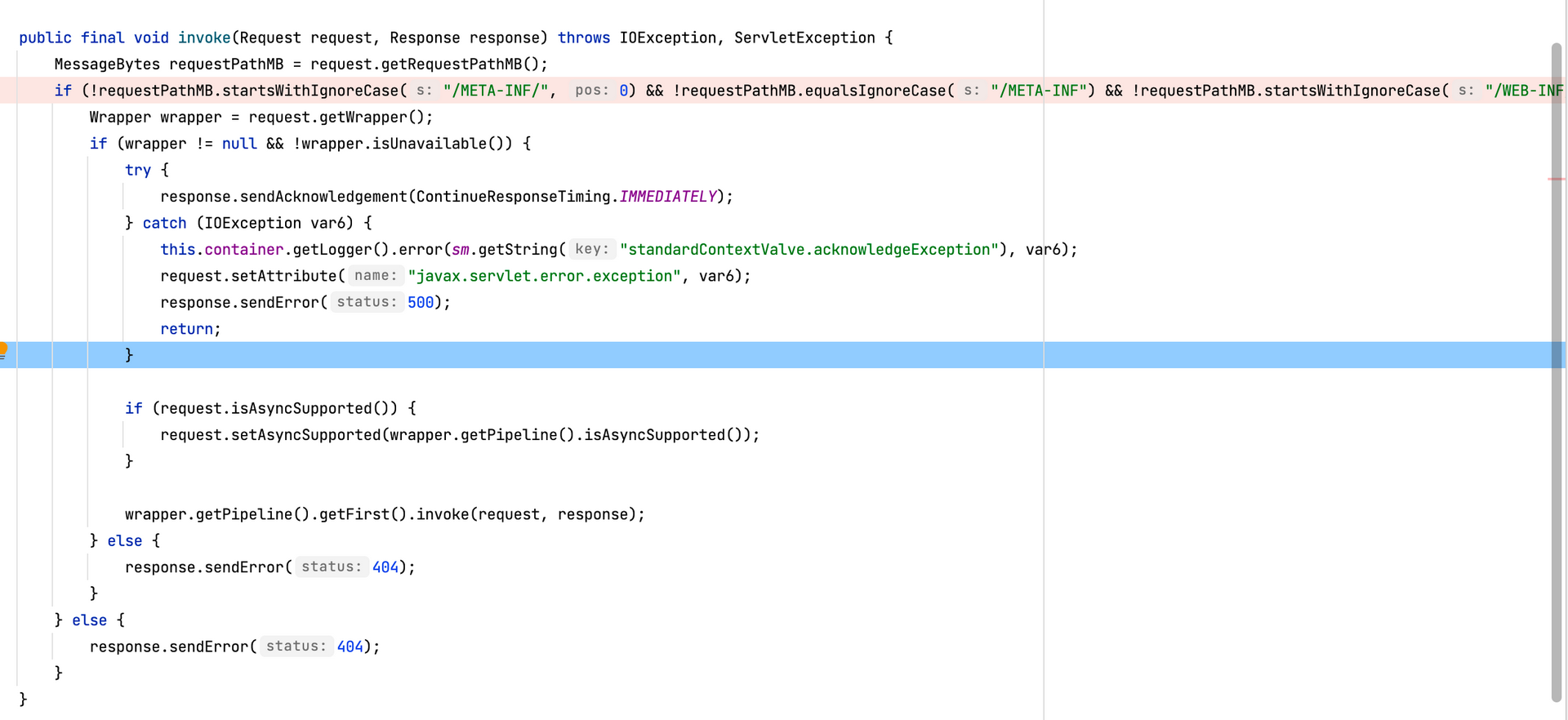
requestPathMB 由来
其中requestPathMB 是调用org.apache.catalina.connector.Request mappingData 属性中的 requestPath值

mappingData 是 final修饰,org.apache.catalina.mapper.MappingData保存了线程中 对应的 Host、Context 、 甚至处理的Wrapper(Servlet)信息。
重新跟入 tomcat 数据处理,查看 Request 构造过程,包括 requestPath 赋值。
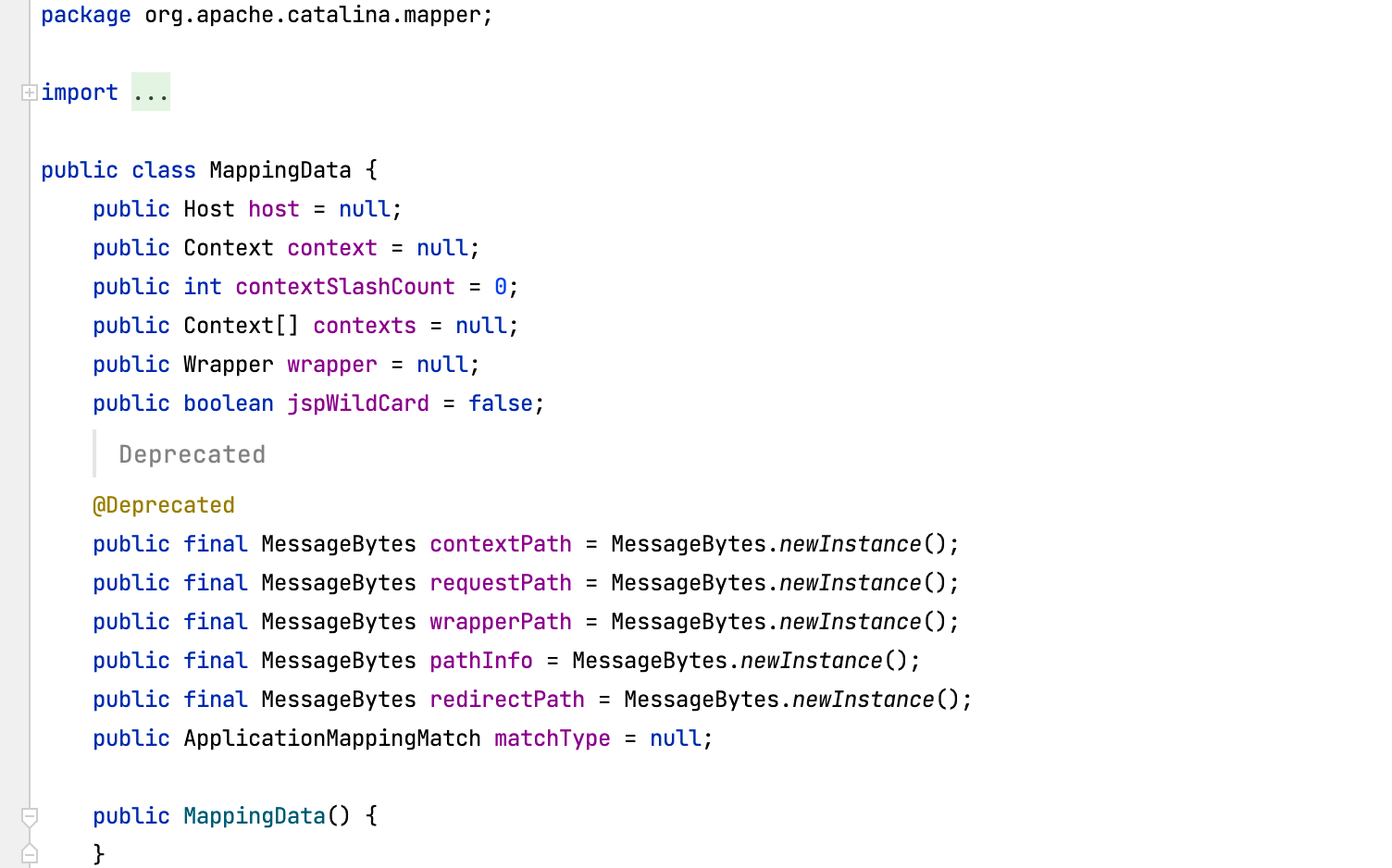
CoyoteAdapter 构建 Request 对象
org.apache.catalina.connector.Request.mappingData 的 requestPath 则是由 org.apache.catalina.connector.CoyoteAdapter 构造, 从更加底层的 org.apache.coyote.Request 封装 交由 容器 Engine 处理。
详见 org.apache.catalina.connector.CoyoteAdapter#service 方法处理请求,该方法创建 Request 和 Response对象,最后将请求交给对应 Engine 的 Pipeline 进行处理
注:req 对象 是 org.apache.coyote.Request 类。
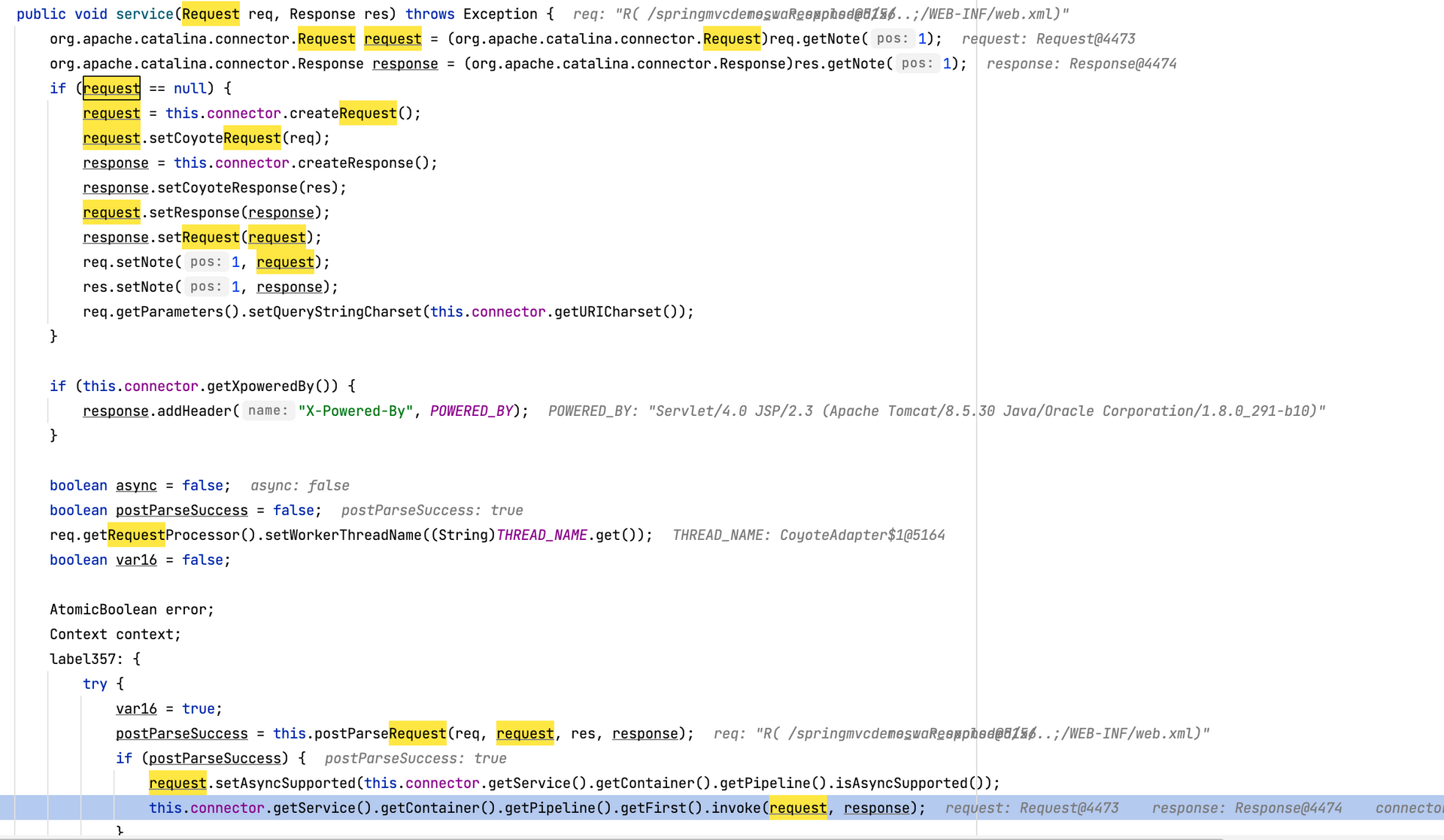
重点关注 postParseRequest
postParseRequest 方法
参考:https://www.cnblogs.com/jiaan-geng/p/4894832.html
- 解析请求url中的参数;
- URI decoding的转换;
- 调用normalize方法判断请求路径中是否存在””, “//”, “/./”和”/../”,如果存在则处理结束;
- 调用convertURI方法将字节转换为字符;
- 调用checkNormalize方法判断uri是否存在””, “//”, “/./”和”/../”,如果存在则处理结束;
- 调用Connector的getMapper方法获取Mapper,然后调用Mapper的map方法(见代码清单11)对host和context进行匹配(比如http://localhost:8080/manager/status会匹配host:localhost,context:/manager),其实质是调用internalMap方法;
- 使用ApplicationSessionCookieConfig.getSessionUriParamName获取sessionid的key,然后获取sessionid;
- 调用parseSessionCookiesId和parseSessionSslId方法查找cookie或者SSL中的sessionid。
/**
* Parse additional request parameters.
*/
protected boolean postParseRequest(org.apache.coyote.Request req,
Request request,
org.apache.coyote.Response res,
Response response)
throws Exception {
// 省略前边的次要代码
parsePathParameters(req, request);
// URI decoding
// %xx decoding of the URL
try {
req.getURLDecoder().convert(decodedURI, false);
} catch (IOException ioe) {
res.setStatus(400);
res.setMessage("Invalid URI: " + ioe.getMessage());
connector.getService().getContainer().logAccess(
request, response, 0, true);
return false;
}
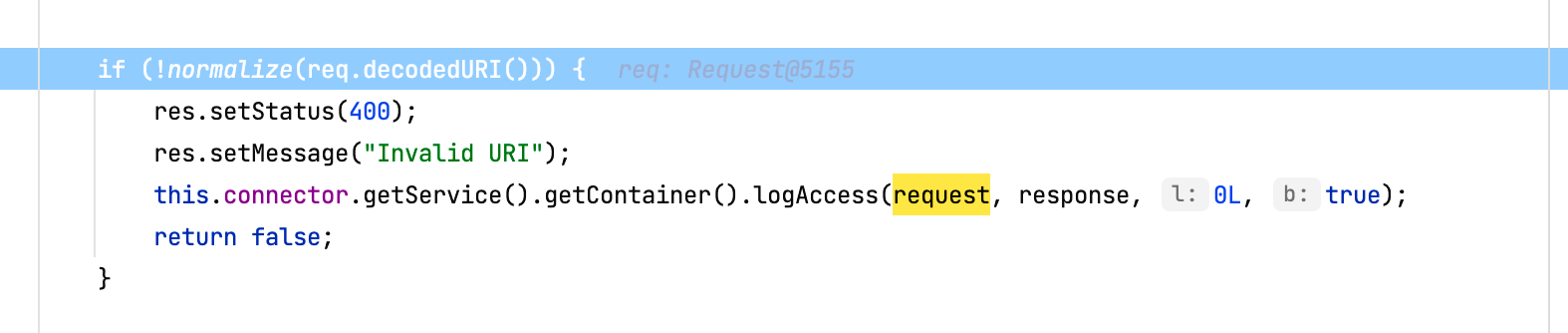
// Normalization
if (!normalize(req.decodedURI())) {
res.setStatus(400);
res.setMessage("Invalid URI");
connector.getService().getContainer().logAccess(
request, response, 0, true);
return false;
}
// Character decoding
convertURI(decodedURI, request);
// Check that the URI is still normalized
if (!checkNormalize(req.decodedURI())) {
res.setStatus(400);
res.setMessage("Invalid URI character encoding");
connector.getService().getContainer().logAccess(
request, response, 0, true);
return false;
}
// Set the remote principal
...
// Set the authorization type
...
// Request mapping.
MessageBytes serverName;
if (connector.getUseIPVHosts()) {
serverName = req.localName();
if (serverName.isNull()) {
// well, they did ask for it
res.action(ActionCode.ACTION_REQ_LOCAL_NAME_ATTRIBUTE, null);
}
} else {
serverName = req.serverName();
}
if (request.isAsyncStarted()) {
//TODO SERVLET3 - async
//reset mapping data, should prolly be done elsewhere
request.getMappingData().recycle();
}
connector.getMapper().map(serverName, decodedURI,
request.getMappingData());
request.setContext((Context) request.getMappingData().context);
request.setWrapper((Wrapper) request.getMappingData().wrapper);
// Filter trace method
if (!connector.getAllowTrace()
&& req.method().equalsIgnoreCase("TRACE")) {
...
}
// Now we have the context, we can parse the session ID from the URL
// (if any). Need to do this before we redirect in case we need to
// include the session id in the redirect
if (request.getServletContext().getEffectiveSessionTrackingModes()
.contains(SessionTrackingMode.URL)) {
// Get the session ID if there was one
...
}
// Possible redirect
MessageBytes redirectPathMB = request.getMappingData().redirectPath;
if (!redirectPathMB.isNull()) {
...
}
// Finally look for session ID in cookies and SSL session
parseSessionCookiesId(req, request);
parseSessionSslId(request);
return true;
}
其中关注两个重要点
parsePathParameters
org.apache.catalina.connector.CoyoteAdapter#parsePathParameters
该方法用于解析路径参数中的 cookie 信息,通常情况下可能保存有 sessionId,
使用样例 /path/Servlet;name=value;name2=value2?name3=value3
对请求参数中的 ; 进行了清理,tomcat 会处理路径中的 ; ,由于该特性,;通常是用来绕过 nginx 等代理
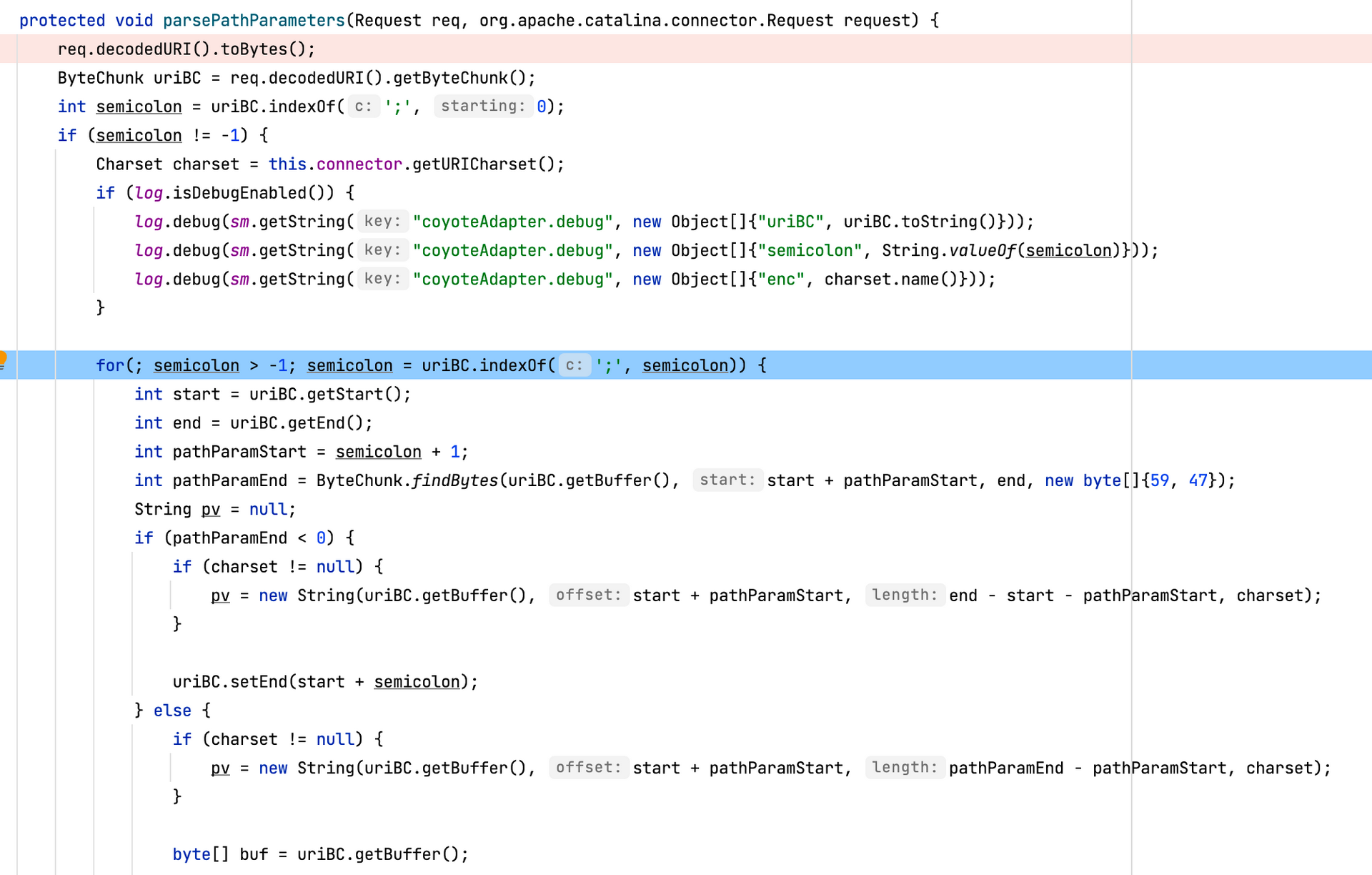
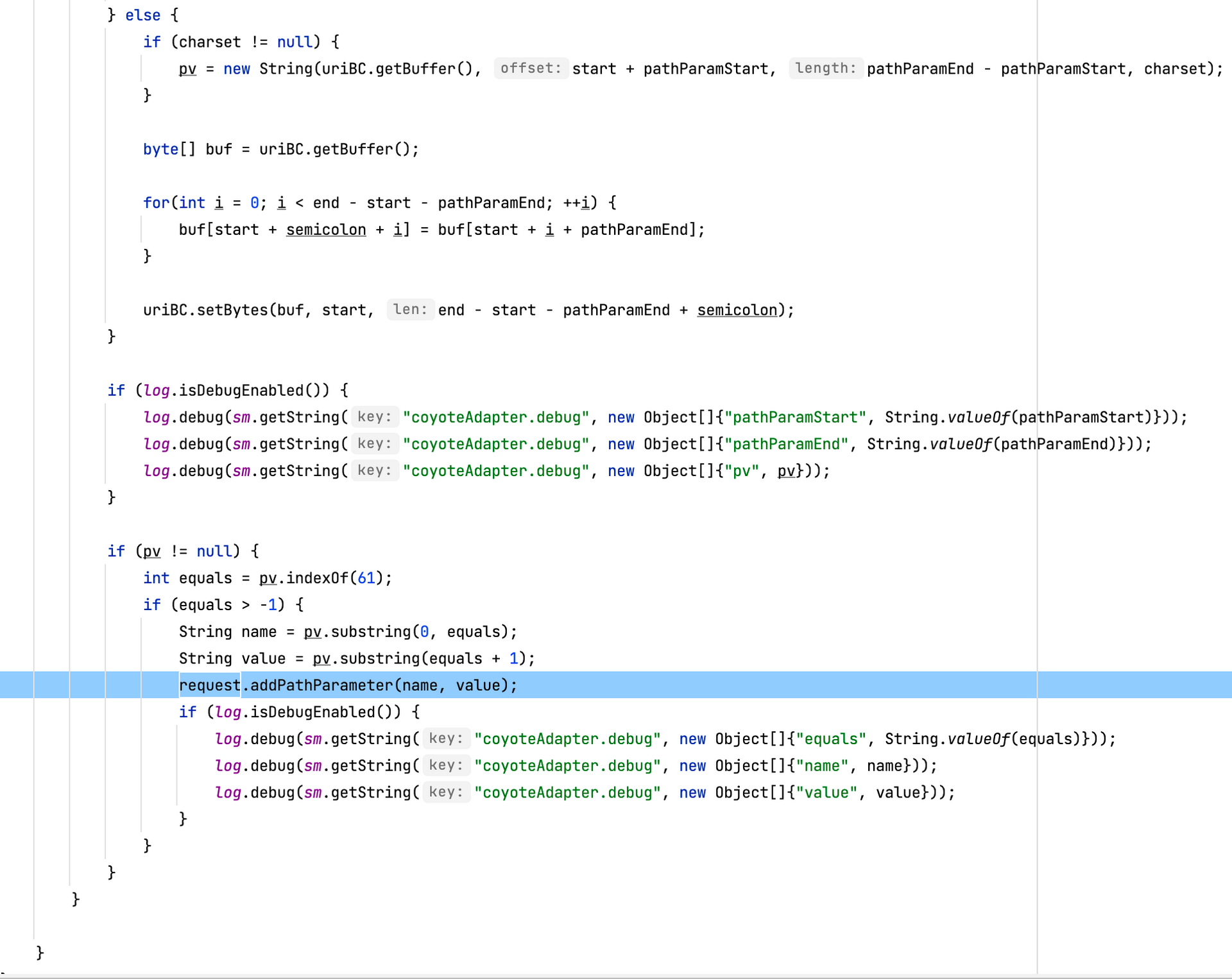
此处进行了一次判断
map
org.apache.catalina.mapper.Mapper 完成了 url , Host, Context,Wrapper 等容器的映射,并最终存储在 MappingData中
在 map
this.connector.getService().getMapper().map(serverName, decodedURI, version, request.getMappingData());
public void map(MessageBytes host, MessageBytes uri, String version, MappingData mappingData) throws IOException {
...
this.internalMap(host.getCharChunk(), uri.getCharChunk(), version, mappingData);
}
private final void internalMap(CharChunk host, CharChunk uri, String version, MappingData mappingData) throws IOException {
mappingData.host = (Host)mappedHost.object;
...
mappingData.contextPath.setString(context.name);
mappingData.context = (Context)contextVersion.object;
mappingData.contextSlashCount = contextVersion.slashCount;
...
this.internalMapWrapper(contextVersion, uri, mappingData);
}
internalMapWrapper 会进行路径映射,找到对应的 servlet
参考:https://www.freesion.com/article/742140485/
- Rule 1 – Exact Match:精确匹配,匹配web.xml配置的格式如
<url-pattern>/testQiu</url-pattern>的Servlet - Rule 2 – Prefix Matcha:前缀匹配,匹配的Servlet格式如
<url-pattern>/testQiu/*</url-pattern> - Rule 3 – Extension Match:扩展匹配,匹配jsp或者jspx
- Rule 4a – Welcome resources processing for exact macth:
- Rule 4b – Welcome resources processing for prefix match:
- Rule 4c – Welcome resources processing for physical folder:
- Rule 7 –如果前面6条都没匹配到,那就返回org.apache.catalina.servlets.DefaultServlet。
private final void internalMapWrapper(Context context, CharChunk path,
MappingData mappingData)
throws Exception {
int pathOffset = path.getOffset();
int pathEnd = path.getEnd();
int servletPath = pathOffset;
boolean noServletPath = false;
int length = context.name.length();
if (length != (pathEnd - pathOffset)) {
servletPath = pathOffset + length;
} else {
noServletPath = true;
path.append('/');
pathOffset = path.getOffset();
pathEnd = path.getEnd();
servletPath = pathOffset+length;
}
path.setOffset(servletPath);
// Rule 1 -- Exact Match
Wrapper[] exactWrappers = context.exactWrappers;
internalMapExactWrapper(exactWrappers, path, mappingData);
// Rule 2 -- Prefix Match
boolean checkJspWelcomeFiles = false;
Wrapper[] wildcardWrappers = context.wildcardWrappers;
if (mappingData.wrapper == null) {
internalMapWildcardWrapper(wildcardWrappers, context.nesting,
path, mappingData);
if (mappingData.wrapper != null && mappingData.jspWildCard) {
char[] buf = path.getBuffer();
if (buf[pathEnd - 1] == '/') {
/*
* Path ending in '/' was mapped to JSP servlet based on
* wildcard match (e.g., as specified in url-pattern of a
* jsp-property-group.
* Force the context's welcome files, which are interpreted
* as JSP files (since they match the url-pattern), to be
* considered. See Bugzilla 27664.
*/
mappingData.wrapper = null;
checkJspWelcomeFiles = true;
} else {
// See Bugzilla 27704
mappingData.wrapperPath.setChars(buf, path.getStart(),
path.getLength());
mappingData.pathInfo.recycle();
}
}
}
if(mappingData.wrapper == null && noServletPath) {
// The path is empty, redirect to "/"
mappingData.redirectPath.setChars
(path.getBuffer(), pathOffset, pathEnd);
path.setEnd(pathEnd - 1);
return;
}
// Rule 3 -- Extension Match
Wrapper[] extensionWrappers = context.extensionWrappers;
if (mappingData.wrapper == null && !checkJspWelcomeFiles) {
internalMapExtensionWrapper(extensionWrappers, path, mappingData);
}
// Rule 4 -- Welcome resources processing for servlets
if (mappingData.wrapper == null) {
boolean checkWelcomeFiles = checkJspWelcomeFiles;
if (!checkWelcomeFiles) {
char[] buf = path.getBuffer();
checkWelcomeFiles = (buf[pathEnd - 1] == '/');
}
if (checkWelcomeFiles) {
for (int i = 0; (i < context.welcomeResources.length)
&& (mappingData.wrapper == null); i++) {
path.setOffset(pathOffset);
path.setEnd(pathEnd);
path.append(context.welcomeResources[i], 0,
context.welcomeResources[i].length());
path.setOffset(servletPath);
// Rule 4a -- Welcome resources processing for exact macth
internalMapExactWrapper(exactWrappers, path, mappingData);
// Rule 4b -- Welcome resources processing for prefix match
if (mappingData.wrapper == null) {
internalMapWildcardWrapper
(wildcardWrappers, context.nesting,
path, mappingData);
}
// Rule 4c -- Welcome resources processing
// for physical folder
if (mappingData.wrapper == null
&& context.resources != null) {
Object file = null;
String pathStr = path.toString();
try {
file = context.resources.lookup(pathStr);
} catch(NamingException nex) {
// Swallow not found, since this is normal
}
if (file != null && !(file instanceof DirContext) ) {
internalMapExtensionWrapper(extensionWrappers,
path, mappingData);
if (mappingData.wrapper == null
&& context.defaultWrapper != null) {
mappingData.wrapper =
context.defaultWrapper.object;
mappingData.requestPath.setChars
(path.getBuffer(), path.getStart(),
path.getLength());
mappingData.wrapperPath.setChars
(path.getBuffer(), path.getStart(),
path.getLength());
mappingData.requestPath.setString(pathStr);
mappingData.wrapperPath.setString(pathStr);
}
}
}
}
path.setOffset(servletPath);
path.setEnd(pathEnd);
}
}
注意,处理时的 path 是经过 urldecode 和 normalize 规范化的。如果直接访问 /;/WEB-INF/web.xml ,路径再被清理之后是不能通过 StandardContextValve的处理的 。
jira 静态文件处理
看了下师傅们将漏洞点定位在 静态文件处理处,https://xz.aliyun.com/t/10109
jira 的静态文件处理逻辑如下,使用 UrlRewriteFilter 处理,属于第三方库
<filter-mapping>
<filter-name>UrlRewriteFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<filter>
<filter-name>UrlRewriteFilter</filter-name>
<filter-class>org.tuckey.web.filters.urlrewrite.UrlRewriteFilter</filter-class>
</filter>
UrlRewriteFilter 介绍
<dependency>
<groupId>org.tuckey</groupId>
<artifactId>urlrewritefilter</artifactId>
<version>4.0.3</version>
</dependency>
看了下介绍,将动态网页地址转换为静态地址,隐藏路径,
maven 最新版本 4.0.4 2012年更新,
官网 http://tuckey.org/urlrewrite/
参考: https://www.cnblogs.com/dennisit/p/3177108.html
可配置属性,allowConfSwapViaHttp 有点意思,一般情况应该不会开启
String confReloadCheckIntervalStr = filterConfig.getInitParameter("confReloadCheckInterval");
String confPathStr = filterConfig.getInitParameter("confPath");
String statusPathConf = filterConfig.getInitParameter("statusPath");
String statusEnabledConf = filterConfig.getInitParameter("statusEnabled");
String statusEnabledOnHosts = filterConfig.getInitParameter("statusEnabledOnHosts");
String allowConfSwapViaHttpStr = filterConfig.getInitParameter("allowConfSwapViaHttp");
if (!StringUtils.isBlank(allowConfSwapViaHttpStr)) {
this.allowConfSwapViaHttp = "true".equalsIgnoreCase(allowConfSwapViaHttpStr);
}
默认的 confpath /WEB-INF/urlrewrite.html
使用本机host 访问时,可以访问到 rewrite-status,输出 已配置的url 转发逻辑
可以修改请求 host 头 127.0.0.1绕过,而且将请求完全响应,也没有做 xss 防御,是个自 x 的点了,危害不大。
urlrewrite.xml 的配置如下
<urlrewrite>
<!-- Caching of static resources -->
<class-rule class="com.atlassian.jira.plugin.webresource.CachingResourceDownloadRewriteRule"/>
<!-- @since 5.0 [KickAss]-->
<rule>
<from>^/issues(\?.*)?$</from>
<to type="permanent-redirect">issues/$1</to>
</rule>
</urlrewrite>
CachingResourceDownloadRewriteRule
com.atlassian.jira.plugin.webresource.CachingResourceDownloadRewriteRule 类用于处理静态文件
该类逻辑: 提供了 pattern 正则匹配模式,匹配到就进行转发
private static final Pattern PATHS_ALLOWED = Pattern.compile("^/s/(.*)/_/((?i)(?!WEB-INF)(?!META-INF).*)");
static Matcher createMatcher(String input) {
return PATHS_ALLOWED.matcher(decodeURLSafely(input));
}
public RewriteMatch matches(HttpServletRequest request, HttpServletResponse response) {
final Matcher regexMatcher = createMatcher(this.getNormalisedPathFrom(request));
if (!regexMatcher.matches()) {
return null;
} else {
final String rewrittenUriPath = "/" + regexMatcher.group(2);
final String rewrittenUrl = request.getContextPath() + rewrittenUriPath;
return new RewriteMatch() {
public String getMatchingUrl() {
return rewrittenUrl;
}
public boolean execute(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
ResourceDownloadUtils.addPublicCachingHeaders(request, response);
request.setAttribute("cachingHeadersApplied", true);
request.setAttribute("_statichash", regexMatcher.group(1));
request.getRequestDispatcher(rewrittenUriPath).forward(request, response);
return true;
}
};
}
}
Pattern.compile("^/s/(.*)/_/((?i)(?!WEB-INF)(?!META-INF).*)") 大致理解下该正则表达式 /_/后不为 WEB-INF 或者 META-INF(大小写都不行)
转发路径样例
/s/a/_/WEB-INF/web.xml 转发为 /WEB-INF/web.xml,
由于 /_/ 不为 WEB-INF ,所以 添加 ; 进行绕过 /s/a/_/;/WEB-INF/web.xml
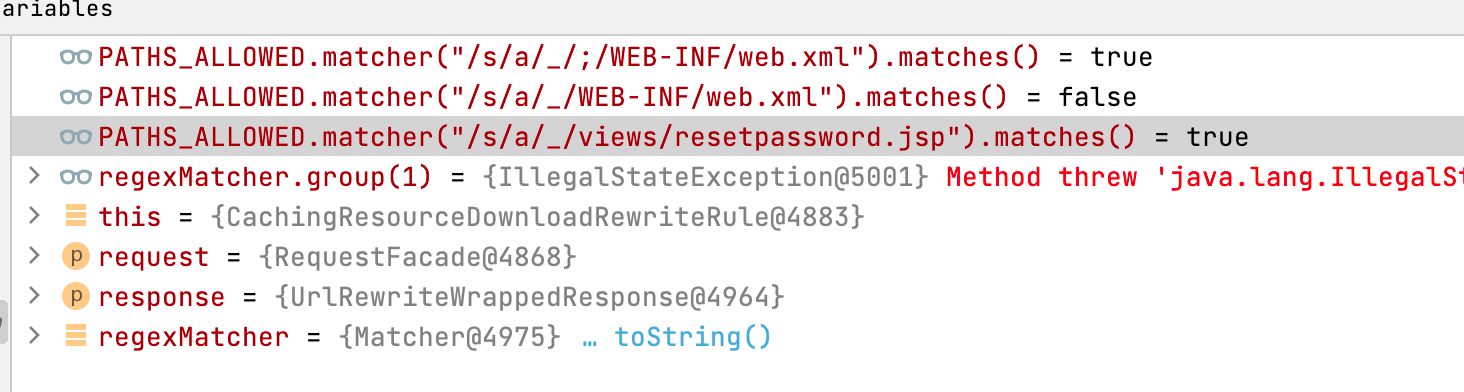
Dispatcher转发逻辑
请求转发使用 request.getRequestDispatcher(rewrittenUriPath).forward(request, response), 此刻 rewrittenUriPath 是 /;/WEB-INF/web.xml
参考:https://www.freesion.com/article/742140485/
通过 org.apache.catalina.connector.Request#getRequestDispatcher(String) 请求调度器。
会交由 ServletContext来处理,ServletContext是web项目的一个上下文,包含所有的Servlet集合,还定义了一些Servlet与容器之间交互的接口。
org.apache.catalina.core.ApplicationContext#getRequestDispatcher 会调用 stripPathParams和 normalize对路径进行规范化
public RequestDispatcher getRequestDispatcher(String path) {
//...
//路径规范化
String uriNoParams = stripPathParams(uri);
String normalizedUri = RequestUtil.normalize(uriNoParams);
//mappingData 赋值,对 request 中 对应的 Host、Context 和 Wrapper,pathinfo 进行赋值
context.getMapper().map(uriMB, mappingData);
Wrapper wrapper = (Wrapper) mappingData.wrapper;
String wrapperPath = mappingData.wrapperPath.toString();
String pathInfo = mappingData.pathInfo.toString();
mappingData.recycle();
// Construct a RequestDispatcher to process this request
return new ApplicationDispatcher
(wrapper, uriCC.toString(), wrapperPath, pathInfo,
queryString, null);
}
关注 context.getMapper().map(uriMB, mappingData); 重新寻找匹配到的 servlet,并对 mappingData 进行赋值。
第二次没有找到相对应的servlet ,使用 org.apache.catalina.servlets.DefaultServlet, 该 servlet 是用于资源文件读取。
修复
对正则表达式进行了完善
Pattern PATHS_DENIED = Pattern.compile("[^a-zA-Z0-9]((?i)(WEB-INF)|(META-INF))[^a-zA-Z0-9]")
结论
漏洞源自于 jira 的静态文件处理类的正则表达式被绕过,利用了 ; 在tomcat中间件进行url解析,转发时会作为参数被提取,清理的特性。
参考
- https://jira.atlassian.com/browse/JRASERVER-72695
- https://tttang.com/archive/1323/
- https://www.html.cn/site/server/1142687689100.html
- https://www.cnblogs.com/jiaan-geng/p/4894832.html
- https://www.freesion.com/article/742140485/
- https://xz.aliyun.com/t/10109
- http://tuckey.org/urlrewrite/